

ハイパフォーマンスコンピュータランキング

2019年11月に米国コロラド州デンバーでハイパフォーマンスコンピューティング(HPC)に関する最大の学会・展示会であるSC19が開催されました。この学会・展示会で計算機の世界的な計算性能ランキングであるTOP500、GREEN500、HPCGなどが発表されます。TOP500はLINPACKと呼ばれる一次方程式を解くベンチマークによるランキングです。LINPACKは「倍精度の浮動小数点演算」※1の計算が実行時間のほとんどを占めて、メモリを読み書きする時間の割合が少ないという特徴があります。そのため、LINPACKの性能は、実際のアプリケーション性能とあまり相関がない、といった批判があります。しかし、1993年からずっと同じベンチマークを使ってランキングが行われているため、時間的な比較、例えば、計算機アーキテクチャの変化を把握することができる、というメリットもあります。
TOP500とは別の観点から計算機を比較するために、HPCG(High Performance Conjugate Gradient)というランキングも2014年から行われています。HPCGで使用されるベンチマークプログラムはLINPACKに比べて、メモリを読み書きする割合が大きいためメモリ性能がランキングに影響する、という特徴があります。TOP500とHPCGのランキング1位は同じSummitという米国エネルギー省の計算機ですが、その性能値を比較してみると、LINPACKが148.6PFlop/s※2であるのに対して、HPCGは2.92PFlop/sと50分の1ぐらいの値であることが分かります。メモリ性能を上げるのは、計算性能を上げるよりも難しいとも言えます。
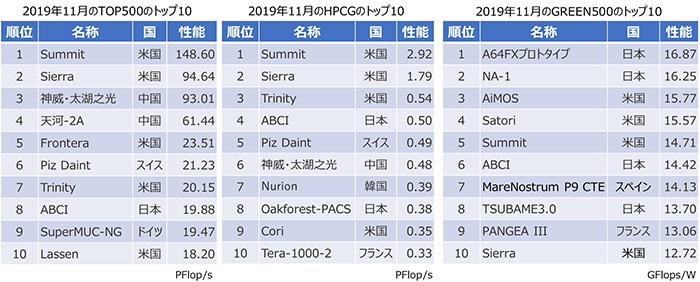
また、計算機の性能だけでなく、消費電力あたりの計算性能が高い計算機をランキングした、GREEN500と呼ばれるランキングも公表されています。計算性能を高めるために、計算機の規模が大きくなり、消費電力が増大していったことに対して、より省電力な計算機を作るモチベーションを向上させるために作られたランキングです。 GREEN500は2007年から発表され、当初はTOP500とは別のセッティングでベンチマークプログラムを実行した時の電力を元に登録できましたが、2016年からはTOP500と統合され、同一の条件で測定し、TOP500にランクインしたシステムがGREEN500に登録されるようになりました。
TOP500では米国と中国が激しく競っています。TOP500にランクインした計算機の国別台数を見ると、中国が227台で1位、米国が118台で2位、日本は29台で3位です。台数では中国が米国の2倍近く多いのですが、ランクインした計算機の性能を合計した値で比較すると、米国が全体の性能の37.8%を占め、中国の31.8%を抜いてトップとなります。したがって、米国には中国よりも大規模な計算機が多くあることが分かります。
いずれのランキングのトップ10にも日本の計算機が入っており、産業技術総合研究所のAI Bridging Cloud Infrastructure(ABCI)は全てのランキングに入っています。日本の登録数が一番多いGREEN500の1位は、2021年度からの運用を目指して開発・製造が進められている理化学研究所の「富岳」プロトタイプ、2位はExaScaler社とPEZY Computing社が開発したNA-1という計算機で、いずれも日本の計算機です。「富岳」プロトタイプの電力性能は16.876GFlops/Wでトップですが、昨年11月のGREEN500でのトップの電力効率は17.604GFlops/Wで、今回のトップよりも高い電力性能でした。
この計算機は、理化学研究所に設置されたExaScaler社とPEZY Computing社のShoubu System Bですが、2019年11月のTOP500にランクインしていないため、GREEN500のリストから落ちました。その後ExaScaler社はNA-1の電圧パラメーターを調整することで、18.43GFlops/Wを達成したとニュースリリース※3で発表しています。このように、GREEN500は性能と電力のバランスでランクが決まるため調整できるパラメーターが多く、計算性能が低い計算機でも上位にランクインできるなど、ランキングが激しく変化する印象があります。
ハイパフォーマンスコンピュータにおけるアーキテクチャの変遷とソフトウェア
TOP500は20年以上に渡って使われてきたベンチマークなので、TOP500のトップ3を1995/11、2003/11、2011/11、2019/11というように8年ごとに並べてみると計算機のアーキテクチャの変化が分かります。
当初はベクトル計算機であったものが、1つの命令で単一のデータ(スカラ)を処理する「スカラプロセッサ」※4で構成された「並列計算機」※5、1つの命令で複数のデータ(ベクトル)をまとめて処理する「ベクトルプロセッサ」※6で構成された並列計算機、画像処理だけでなく、画像処理以外の計算も行えるようにした「GPGPU」※7とスカラプロセッサで構成された並列計算機というように変化してきています。

GPGPUを使うことで、電力当たりの計算性能を向上させることもできます。GREEN500で見ると2019年11月のトップ30のうち、27台の計算機がGPGPUを使ったクラスタ構成の計算機になっています。また、「京」もGPGPUは使っていませんが、HPC-ACEと呼ばれる「SIMD」※8処理ができるプロセッサになっていて、1つの命令で複数のデータを処理するベクトル的アプローチによって計算性能を高めています。
また、「富岳」のCPUもSVE(Scalable Vector Extension)と呼ばれる命令セットを用意して、並列的に処理を行えるようになっています。いずれも、スカラプロセッサですが、アクセラレータを内蔵したアーキテクチャのプロセッサです。
GPGPUやアクセラレータを使って演算性能を高めるためには、これらの仕組みを十分に使いこなしたライブラリやアプリケーションを用意する必要があります。利用者が自らプログラミングを行って、徹底的に性能を極める、という使い方はできますが、性能チューニングは非常に手間のかかる作業です。ハイパフォーマンスコンピュータ利用者のすそ野を広げるという意味では、使いやすくて性能が良いライブラリを用意したり、プロセッサのアーキテクチャに合わせて自動的に性能チューニングをするコンパイラやツールを用意したりする必要があります。
ハイパフォーマンスコンピューティングで成果を得るためには、速いハードウェアを作るだけでなく、ハードウェアのアーキテクチャに合わせたライブラリやツールといった、ソフトウェアの開発も重要です。それによって、より幅広い利用者にハイパフォーマンスコンピュータを利用してもらえるようになり、より多くの成果をあげることができるようになると期待されます。
日本の存在感がある国際会議
情報処理分野の国際会議で、日本の存在感が大きい国際会議はロボットに関する会議とハイパフォーマンスコンピュータに関する会議だと思います。例えば、毎年米国で開催されるSCの展示会では、日本の企業だけでなく、多くの大学や国研がブースを構えています。
近年、世界中でAIの活用が盛んに行われていますが、ロボットは以前からAIを適用できるアプリケーションとして研究が盛んでしたし、ハイパフォーマンスコンピューティングにおいても、ディープラーニングなどの学習には大量の計算が必要なことから適用分野として有望視されています。そこで、日本は存在感があるロボットやハイパフォーマンスコンピューティング分野を足掛かりにAIの活用分野で成果を出していって欲しいと思いますし、AIに留まらず、ハードウェアだけでなくソフトウェアも含めた日本のICT分野の研究開発が世界で存在感を増していって欲しいと思います。
- ※1 倍精度の浮動小数点演算
倍精度の浮動小数点数を使った演算。単精度に比べて表現できる値の範囲が広く誤差が少ない。倍精度の浮動小数点数は計算機で実数を表現する形式の一つでIEEE(Institute of Electrical and Electronics Engineers)が標準規格として定めている。他に四倍精度の浮動小数点、単精度の浮動小数点、半精度の浮動小数点など、表現できる値の範囲が異なる表現方法がある。 - ※2 PFlop/s
浮動小数点演算の速度を示す単位。Pは国際単位系の接頭辞の一つであるペタの略で、FlopはFloating Pointの略。ペタは10の15乗を表す。10の18乗はエクサ(E)、10の12乗はテラ(T)、10の9乗はギガ(G)、10の6乗はメガ(M)、10の3乗はキロ(K)。1PFlop/sは1秒間に10の15乗回、つまり1京回=1,000,000,000,000,000回の倍精度の浮動小数点演算ができる速度。 - ※3 スーパーコンピュータ「NA-1」がスパコン省エネランキングGreen500で世界第2位と認定 その後、消費電力性能世界記録を更新(2019年12月3日アクセス)
- ※4 スカラプロセッサ
1つの命令で単一のデータ(スカラ)を処理するプロセッサ。パーソナルコンピュータなど、一般的なコンピュータで使用されるCPU(中央演算処理装置)などに用いられている。 - ※5 並列計算機
複数の計算を同時に処理できる計算機。必ずしも同じ計算を同時に処理することは意味しない。ハイパフォーマンスコンピューティングにおける並列計算機はCPUを多数並べて計算を行う。 - ※6 ベクトルプロセッサ
1つの命令で複数のデータ(ベクトル)を並行的にパイプライン化して次々と実行するプロセッサ。科学技術計算分野でよく使われるが、グラフィックス処理等にも使われている。 - ※7 GPGPU
General Purpose computing on Graphics Processing Unitsの略。GPUはリアルタイム画像処理向けの高速な計算などを実行することが目的の専用プロセッサであるが、原理的にベクトル計算機と同様に並列計算もできるため、GPUをプログラム可能にして、画像処理だけでなく、画像処理以外の様々な計算も処理できるようにしたプロセッサ。 - ※8 SIMD
Single Instruction Multiple Dataの略。1つの命令で複数のデータを処理する計算機の並列化アーキテクチャの一つ。複数のデータを同時に処理することで演算性能が上がる。