トーゴーの日シンポジウム2024「AI+ロボティクス+データベースが変える生命科学」招待講演「ロボティック・バイオロジーによる生命科学の加速-生命科学の自律化に向けて-」(科学技術振興機構=JST=主催、2024年10月5日)からー

講演の土台として、まず「ロボティック・バイオロジーによる生命科学の加速」の取り組みをご紹介いたします。続いて、本日の主題である「ラボの自律化から生命科学の情報データベース化へ」として、バイオインフォマティクス(生命情報科学)の長年の夢である生命科学の情報化・データベース化につながるアイデアを共有させていただきます。最後に「『AIロボット駆動型科学』と科学基盤モデル」と題してAIの活用についてお話しいたします。

汎用ヒト型の「まほろ」で実験、デジタルツインも構築
5年ぐらい前からJST未来社会創造事業の一環として「ロボティック・バイオロジー」に取り組んでいます。このプロジェクトのスローガンは、「実験をプログラミングにする」です。将来的に実現を目指すのは、研究者が実験をプログラムすると、ロボットが自動で実験を行い、結果が返ってくる仕組みです。実験プロトコル(手順)と結果は、インターネットを介して即座に共有できるので、別の研究者がダウンロードして追試や実験の改良ができます。これによって生命科学研究を加速させる狙いが根本にあります。
このアイデアを我々は「Laboratory as a Service」、略してLaaS(ラーズ)と呼んでいます。プロトタイプとして、理化学研究所(理研)神戸キャンパスにラボをつくり、汎用ヒト型ロボット「まほろ」による実験や、ロボットと人間の共同作業など、いろいろと試行しているところです。まほろは、人が扱う実験器具や機器をそのまま使えます。自動顕微鏡など他の機器と連携することもできるので、自律的に判断しながら実験を遂行できます。
同時に、実験ロボットのデジタルツイン構築も進めています。産業技術総合研究所の光山統泰さんのチームが仮想空間内に実験室を再現し、バーチャルとリアルのまほろを同期させることで、仮想空間で現実空間の状況を確認したり、仮想空間で行ったシミュレーション結果を現実空間に反映させたりしています。

人の介在なく細胞培養を約10倍加速
応用として注力しているのが、細胞培養です。暗黙知を含めてロボットに実験操作を覚えさせた上で、顕微鏡画像を用いて細胞の形状を機械学習で認識させ、さらにモデルベースという手法で細胞の状態変化を予測させます。それをもとに、ルールベースという手法でロボットに次の操作を判断させるというクローズドループを構築します。
この技術によって、2019年末から2020年にかけての10日間、人の介在なしにロボットが細胞培養を行えたのです。2022年にはAIロボットが、iPS細胞を網膜色素上皮細胞に分化誘導する最適条件を自律的に発見することに成功しました。熟練した専門家でも5年ぐらいかかるといわれるところを半年間で実現させたため、約10倍の研究加速効果があったと考えています。
2023年には、ロボット用細胞培養加工施設(R-CPF)を病院に設置しました。基礎研究で開発したプロトコルや技術を臨床現場にそのまま移行できるようになり、基礎と応用の連携が大きく加速すると見込んでいます。
プラットフォームづくりに自己完結、記述、再現の3要件
では、本題の「ラボの自律化」とは何なのか。今までの「自動化」では、研究者が機器やモノの管理、AIロボットのプログラミングやメンテナンス、次世代ロボットの開発までをも担わなければならず、負荷がかかり過ぎていました。研究者が研究に集中するためには、研究者・運用者・開発者の分業が必要であり、それを可能にする技術が「自律化」なのです。
今の生命科学には「細胞システムの複雑性」「実験の再現性」「データの散逸」などの問題がありますが、LaaSによってこうした問題の解決に迫れるのではないかと考えています。つまり、世界中の実験データをクラウド上で参照可能になり、一つのデータベースに情報が蓄積されていくことによって、生命現象の全貌を明らかできる―生命科学研究は、そうした世界観に向かっていくべきなのではないかと思うのです。
そこで、LaaSの実現のために自律実験プラットフォームをつくろうというわけですが、技術的な要件が3つあると考えています。1つ目が「自己完結性」。これはロボットの実験操作の詳細を、人間が把握しなくて良いということです。2つ目は「記述性」。実験プロトコルや細胞などの試料の情報を、研究者がデジタル上で自由かつ数値的に指定できることです。3つ目は「再現性」。同じ試料に対して同じプロトコルをオーダーすれば、同じ結果が期待されることです。
異種機器を組み合わせ、実験の処理時間半減
この3要件がそろうことによって、世界中の生命科学研究者が努力して取得した実験データが無駄にならずに、きちんと一つのデータベースに蓄積されていきます。過去に似たような実験があれば結果を参照できるので、巨人の肩に乗れるようになるのです。
この実現のために、我々はまず「記述性」に取り組み、実験プロトコル記述言語「LabCode」を開発しています。一つのプログラムでロボットや実験機器、AIを連携して動かせる高級言語(人間が理解しやすいように設計されたプログラム言語)です。
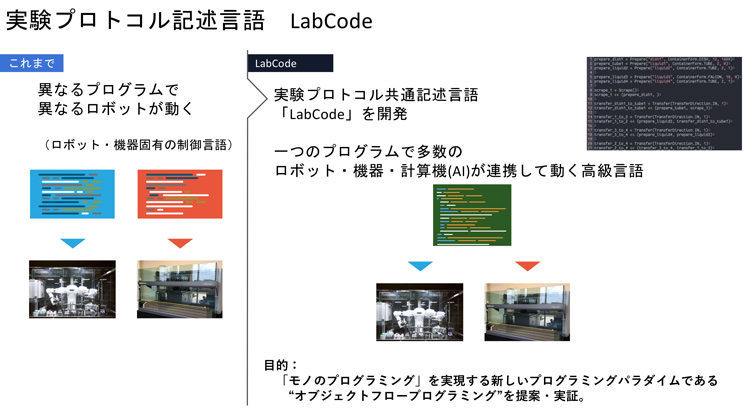
そのための新しいプログラミングパラダイムを提唱していて、それが「オブジェクト・フロー・プログラミング(OFP)」。一つひとつの実験操作を関数で記述して、有向グラフ(矢印などで方向を示した図)として組み合わせることにより、複雑な実験操作を記述することを目指しています。
実験操作のグラフ表現はさまざまな面で有用ですが、そのうちのひとつは実験室内の機器に対する実験操作の割り振りを最適化できることです。異種機器の組み合わせによって、単一機器を使うときに比べて実験の処理時間が50%ほど短縮できるという結果もあります。

大規模言語モデルを活用し、遺伝子やタンパク質で成果
最後はAIの活用についてお話しします。2024年9月に発表された論文によると、自然言語処理の分野において人間とLLM(大規模言語モデル)の研究アイデアを100人以上の専門家が盲検で評価したところ、新規性とインパクトでLLMが人を上回るという驚くべき結果が得られたそうです。
2024年8月にはサカナAI(東京都港区)が、機械学習研究の全自動化に成功したと発表しました。LLMを使って、研究アイデアの生成から新規性のチェック、実験の計画、コードの記述、実験の実行、論文の執筆までを行い、さらに公開査読データで学習して論文をレビューし、その評価をもとに次のアイデアにつなげることができるといいます。
LLMは基盤モデルと呼ばれる汎用性の高いAIの一種です。重要な特徴が「スケール性」で、コンピュータの計算量、データセットのサイズ、自然言語処理モデルの規模(パラメーター数)を大きくするほど、際限なく性能が向上しているように見えます。
生命科学分野の基盤モデルもさまざま開発されています。例えばscGPT、Geneformerなどの細胞の遺伝子発現データの基盤モデルでは、数千万個の細胞データを事前学習して、分類や遺伝子の相互作用の推定などさまざまなタスクに対応できます。
もう一つ重要なのが、タンパク言語モデル。タンパク質のアミノ酸配列を学習させたモデルで、米メタが開発したESM-2では、6500万本のアミノ酸配列を学習させたことでタンパク質の立体構造予測能力が創発したという結果が出ています。
生命システムを「マルチモーダル」として統合へ
問題は、ビッグデータはいつか枯渇すること。では、どうするのか。解決の鍵は「身体性」と考えています。つまり、基盤AIに自らの知識が不足している部分に関する実験条件と結果予測を生成させた上で、ロボットに実験を行わせ、返ってきた実測データと予測の誤差情報を使って学習するサイクルをつくると、ビッグデータがなくてもどんどん賢くなるAIがつくれるというわけです。
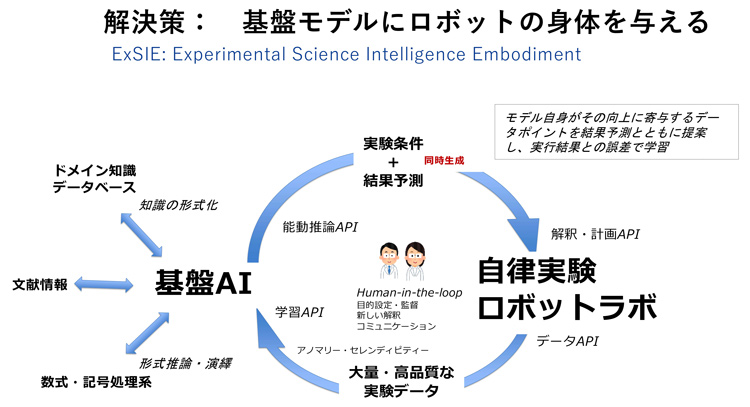
そのアイデアをもとに、今年4月、理研では新しい研究組織である科学研究基盤モデル開発プログラム(AGIS)を立ち上げ、研究を進めています。長期的には複雑な姿をしている生命システムというものを、複数種の情報を同時処理できる「マルチモーダル」な基盤システムとしてデータ駆動で統合できるのではないかと考えています。何年かかるかわかりませんが、目指す価値のある夢だと思っています。

関連リンク
- トーゴーの日シンポジウム2024「AI+ロボティクス+データベースが変える生命科学」
- 理化学研究所 生命機能科学研究センター「高橋恒一」