合成音声と聞いて、あなたはロボットの声を想像しますか?それとも限りなく人間に近い抑揚のついた声を想像しますか?
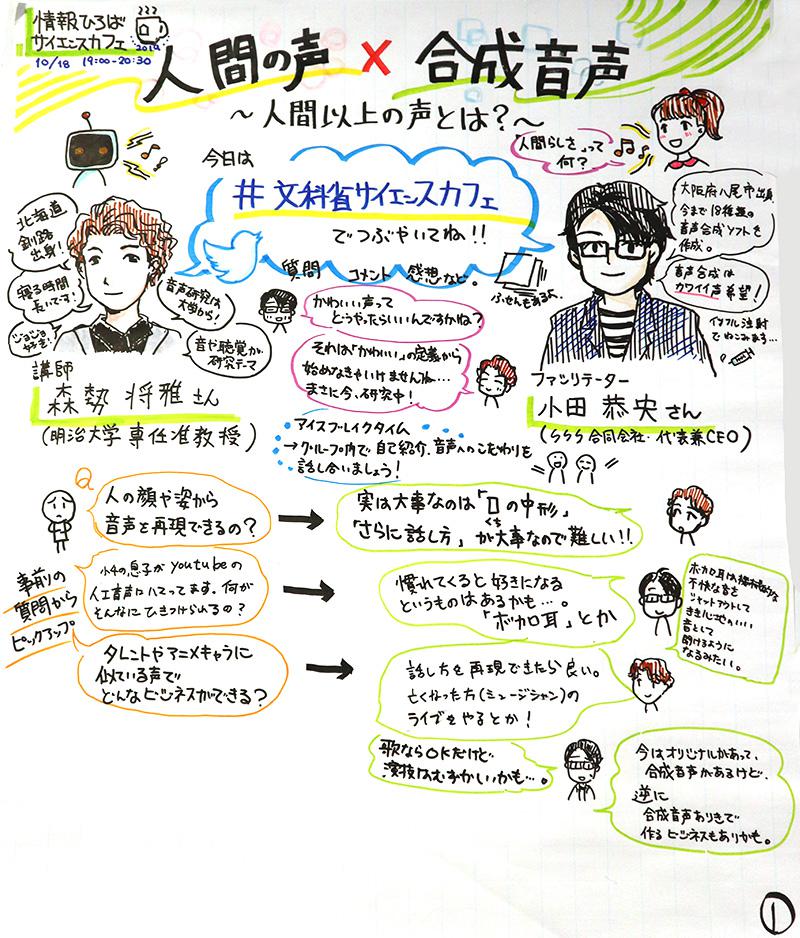
今年度の情報ひろばサイエンスカフェ第4回目のテーマは「人間の声×合成音声〜人間以上の声とは?〜」。文部科学省が主催、科学技術振興機構(JST)が共催して、10月18日(金)に文部科学省(東京都千代田区霞が関)内「情報ひろばラウンジ」で開かれた。このイベントは、11月に行われた「サイエンスアゴラ2019」の連携企画の一環。サイエンスアゴラ2019のテーマである「人間って何?」といった根本的な問いを解き明かすための一つの切り口として、声の技術「合成音声」がテーマに選ばれた。私たちの生活を今後豊かにしてくれるかもしれない合成音声の新しい研究とその可能性を、科学者や専門家と参加者が語り合った。

今回の講師は、明治大学総合数理学部専任准教授の森勢将雅さんだ。「音は脳に作用する数列である」というのが持論で、音や聴覚に関するさまざまな研究を実施してきた。現在は理想の歌声を作成する技術「歌唱デザイン」を支援する技術開発を推進している。
ファシリテーターは、SSS合同会社代表兼CEOの小田恭央さん。自社キャラクター「東北ずん子ちゃん」は、理想とする合成音声の在り方を表現し、「正確な声」よりも「かわいい声」を模索しているという。カフェは、事前に投稿された参加者の質問に答えるかたちで進んだ。
質問の内容から、参加者の多くが合成音声に対して日頃から何らかの関わりを持っていて、非常に関心が高く詳しいことが伺えた。日常生活でのふとした瞬間に感じた素朴な疑問から、かなり専門的な内容まで幅広く質問が寄せられていた。

「合成音声」は人の声に近い方が素晴らしい?ロボット声のままが良い?
人間の声を収録し、収録した声の高さや声色を分析、コンピューター上に再構築したものを「合成音声」という。スマートフォンやスマートスピーカーの普及に伴い、生活のさまざまなシーンで合成された音声を聞く機会が増えている。森勢さんから「合成音声を知っていますか」といった問いかけには全ての人が手を挙げていた。
合成音声と一言にいっても、抑揚のない声から人間の声と区別ができないものまで、実にさまざまだ。合成音声と聞くと、人間に似ているものは高品質、そうでないものはロボット声で人間の声よりも劣る、と考える人もいるかもしれないが、森勢さんは“人間に似て非なる魅力的な音声”というものが存在し、人間にはない機能を備えた合成音声が私たちの生活を豊かにしてくれるかもしれないと考えている。
森勢さんは合成音声がどのように誕生したのか、その歴史から語り始めた。
声の情報量は膨大で、当初はいかに圧縮するかが課題だった。しかし、1997年にコンピューターの性能が上がってから現在まで、音声分析の情報量削減の研究が盛んに行われ、人間の声と同じものをコンピューターでも合成できるような時代になった。
森勢さんの研究の原点は、音声合成に使われるソフトの音声データの圧縮技術だという。通常、音声は符号化(圧縮)され、振幅と時間軸の波形によって示される。1秒間に約8000点もの振幅だ。研究者たちは、人間が聞くことのできる音の周波数の範囲から、本当に必要な音の情報は振幅でいうと実は数十ほどで良いのではないかと考えた。数十ほどの振幅を音声の核として残し、音として表現する。自分たちの耳に届いている音の情報が実は少ないという話を聞いた参加者は、納得するようにうなずいていた。

合成音声は3つの情報が混ざったミックスジュース
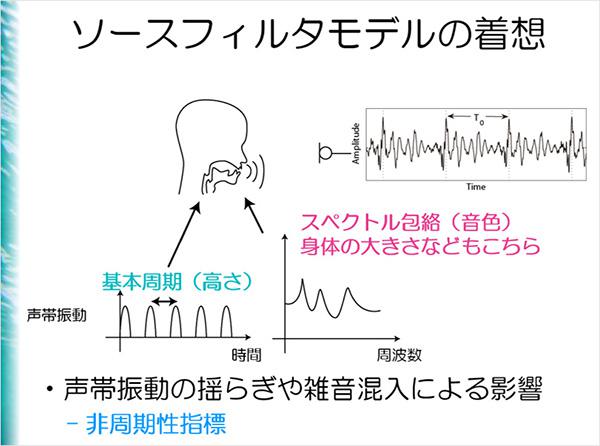
合成音声は、音声を形作る3つの要素、声の高さ(基本周波数)、音色(スペクトル包路)、声のかすれ具合(非周期性指標)を抽出し再合成することで作られる。

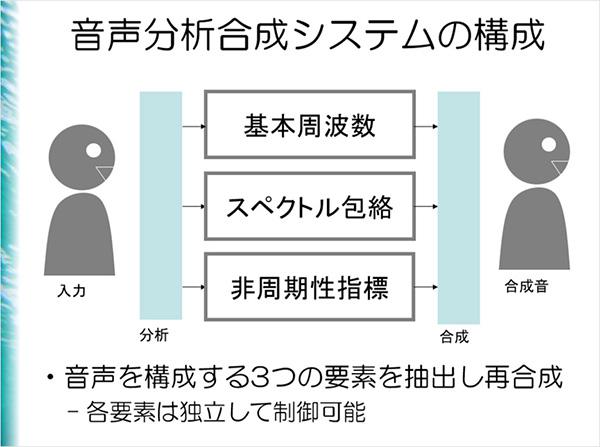
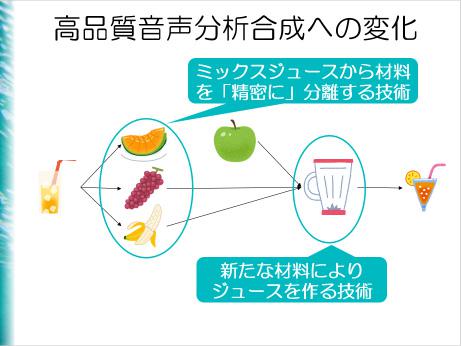
参加者の質問に「人の声を自分の声に変換する方法にはどんなものがあるのか」というものがあった。これに対して森勢さんは「成分を分離する機械と似ている」と答えた。音を分離する性能が悪いと、変えたはずの成分が残り、いわば「正確なミックスジュース」を作ることができないという。つまり、音が悪く、理想の音声にならない。森勢さんは、こうした課題を解決するために、数学における信号処理の技術を使って、余計なものが混ざらず1つの要素を完璧に取り出す技術開発を目指してきたという。ボイスチェンジャーなどのシステム作りだ。音声の波形が入ってきたら、それを高さの情報と音色の情報、それ以外の情報にばらし、その3つのものから合成音声のための波形を作り出す。
男らしい声、女らしい声、で別人に
参加者から「任意の声に変換できるか」「合成音声を聴いた時の違和感は慣れると消えるがこれはなぜなのか」といった疑問が出た。すると森勢さんは参加者とある実験を始めた。「コーヒーにミルクを入れますか?」という台詞を、合成音声とオリジナルの声とでどう違うか聴き比べる実験だ。
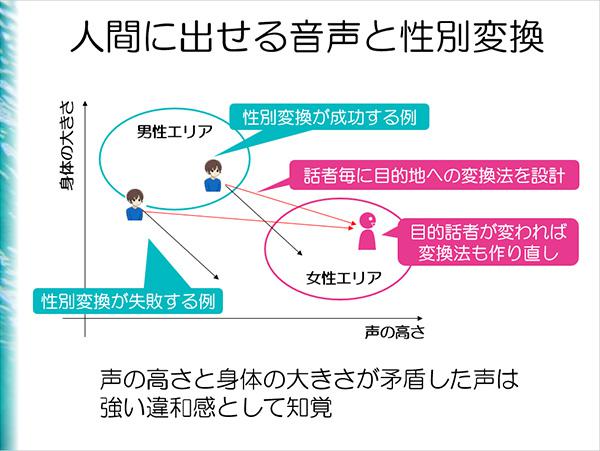
人間に限りなく近い声を目指す場合は、どのような要素が必要になってくるのか。多くの人は声の高さ(声帯)と身体の大きさ(音色)が見合っていない声に対して、強い違和感を覚えるという。声の高さと音色の情報調整は今の技術でもできるため、男らしい声、女らしい声に寄せて調整することも可能だという。
ただ音の高さと音色を表す数値を変更すれば、別の人の声を再現できるわけではない。高低を調節しただけでは、声に一種の不気味さが出る可能性があるという。「例えば、テレビに匿名で出演する人が誰だか分からないようにするため、こもったような響き効果をつけた声を聴いた時に違和感を覚える人も多いだろう」とファシリテーターの小田さんが指摘した。

どのようにすれば、理想とする合成音声を作ることができるか。人の声の高さや音色などは、その人の身体的特徴によって決まる。そのため、理想の合成音声を作るには、声の主となる人物の体格などの情報を算出し反映させることが必要になってくるという。最近の変換ソフトには、「人間の寸法を変える」という機能があり、これを調整することで男らしい声を女らしい声に変換することなどが可能になる。小田さんは、「顔に化粧をするように声にお化粧をする時代がくるのではないか」と考えている。
合成音声の技術をつくることは大変だ
「写真だけで歴史上の人の声を再現できるか」という質問に、森勢さんと小田さんは、今の技術では難しいと答えた。なぜなら、写真からだけでは、先にも挙げている3つの要素(声の高さ・音色・かすれ)や全ての身体的特徴などが分からず、再現するために必要な情報が不足しているからだ。身体的特徴に加えて、「口の中の形状」や「話し方の癖」などの要素も必要になってくる。完全な再現は難しい。
合成音声をつくる時に重要になるのは、声帯だけでなく「口の中の形状」だと森勢さんはいう。人の口の開き方はその都度異なり、その日の気温やその時々の感情など、さまざまな影響を受けるため、同じ人の声でもたくさんの種類があるのだ。
また、喉の構造に関する情報を取り出せば、ある程度の声の癖は模倣できるが「話し方の癖」(スタイル)まで真似するのは難しい。仮にそれらの情報をうまく取り出せたとしても、「話し方の癖」を波形に反映させるという技術が必要になってくる。現状の解決策は、個人の「声の演技力」を磨くか、合成音声ソフトに「演技力」についての項目を付加するしかない、と小田さんはいう。
今後は、人工知能(AI)も活用して「話し方の癖」などをコンピューターに組み込むことにより、ある程度可能になっていくかもしれない、と森勢さん。どのようにデータとして組み込むか、そのシステムの開発が森勢さんの課題であり、また、時間やコストについても考えなければならない、と語った。
特定の誰かの声を真似る技術を開発する際には、最初に必ず誰かを基準としなければならず、作った技術は必ず誰にでも使えるわけではない。合成音声の技術をつくることの大変さや、「話し方の癖」が聴く側にとってとても大事な情報であることが分かった。

合成音声の魅力と可能性
森勢さんの話を踏まえ、「人間を超える音声合成の可能性」というテーマでグループワークが始まった。例えば、聞いただけで眠りに落ちるといった、人間にはない機能を備えた合成音声は私たちの生活を豊かにしてくれるかもしれない、と森勢さん。漫画などでデフォルメされた人間の身体が魅力的なキャラクターとして受け入れられているように、合成音声も同じく、“人間に似て非なる魅力的な音声”は存在するかもしれない。こうしたことを前提に老若男女の参加者は活発に議論した。合成音声に対する日頃の疑問や細かな技術の問題、ビジネスの可能性まで、それぞれのグループで盛り上がったやり取りが続いた。
グループワークの後に各グループから話し合われた内容が発表された。医療分野や避難補助システムなどの防災分野、動物と会話できる装置といった言語を超えたコミュニケーション分野など、多様な可能性が紹介された。参加者は皆、他のグループの発表内容に盛んにうなずいていた。
発表を聞いて森勢さんは、ロボットやキャラクターの世界での「アシスタントが女性」というイメージを変えるために「中性的な声」をつくるシステムなど、現代の技術でもさまざまなシステムが可能ではないかと指摘している。
他の参加者から、モスキート音のように特定の人にしか聞こえない音を合成音声の作成ソフトに組み込めば、脳だけに直接伝わる音を合成する技術ができる可能性があるのではないか、との指摘が出された。これに対し小田さんは、人間が聴覚などの刺激に対して心地良いと感じる感覚や反応である「AMSR」について説明し、そのような「音を解明していく研究」が心理学の分野で進んで合成音声の技術と組み合わされば、近未来SFのように普通の「声」を使わない会話が実現するのではないか、とコメントしていた。
最後に、「合成音声に対する感覚」の話があった。デジタルネイティブ世代とそれ以前の世代で、合成音声に対する感覚や意識の違いがあるかどうかについて議論になった。結論は出なかったが、音声合成用の音源「初音ミク」の例が取り上げられ「生まれたときから初音ミクを聞いている人は当たり前のように聞いている」。要は慣れの問題ではないかという指摘だ。私たちは普段の会話に慣れているので、方言をずっと聞いていると違和感がなくなってきて「当たり前」になるのと同じような現象が起きているのではないかと小田さん。多くの話題で議論は尽きなかった。

合成音声が人間の声を超えることや生活を豊かにすることについて、たくさんの研究が進んでいる。合成音声で生み出せるものはとても幅広く、可能性に満ちあふれている。現在の研究レベルでは、人間はまだその可能性のごく一部にしか気がついていないのかもしれない。合成音声は、「ロボットの声」なのか「限りなく人間に近い声」なのかという二元論でなく、多様な解釈をすることで、より合成音声の魅力に気がつくことができるかもしれない。
参加者の多くは、研究やビジネスを念頭に参加した者が多かったようだが、社会的な意義を考えるきっかけにもなったという声もあった。登壇者・参加者ともに得るものがある満足感の高いサイエンスカフェだったと感じた。
 ギジログ1 | 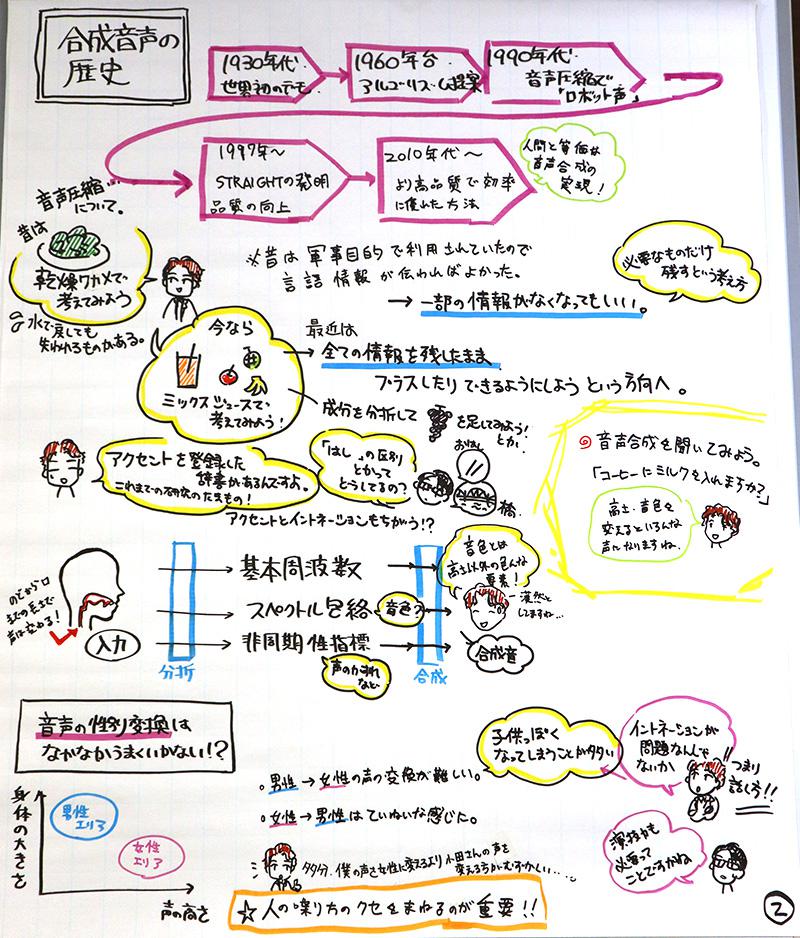 ギジログ2 |  ギジログ3 |
サイエンスカフェをまとめたギジログ(「ギジログガールズ」の加藤麗子さんと高良玉代さんによる)
関連リンク