


クラウドコンピューティングとは
クラウドコンピューティング」という言葉は、2006年、Google社CEOのエリックシュミット氏による「英国「The Economist」の特別号への寄稿文」で用いられたのが最初と言われる。情報やその処理が、固定された特定の場所ではなく「インターネット上に雲のように広がる、分散した環境の中で行われる情報処理の形態」といった意味である。その後この言葉は、いわゆる“バズワード”として独り歩きし、様々な人から様々な意味で用いられるようになったが、米国の国立標準技術研究所(NIST:National Institute of Standards and Technology)では「(ユーザにとって)最小限の管理労力、あるいはサービス提供者とのやりとりで、迅速に利用開始あるいは利用解除できる構成変更可能な計算機要素(例えばネットワーク、サーバ、ストレージ、アプリケーション、サービス)からなる共有資源に対して、簡便かつ要求に即応できる(オンデマンド)ネットワークアクセスを可能にするモデルである」(2009年10月7日)と定義している。
つまり「装置を柔軟に再構成し、必要に応じてその処理能力を大きくしたり小さくしたり容易に変化させられるシステムから、ネットワークを介して、情報処理サービスを提供するモデル」というような意味となる。
情報処理システムにこのような特性を持たせる試み自体は「オンデマンドサービス」などの用語とともに存在し、特に新しいものではなかったが、「仮想化」と「並列化」の2大技術の革新により、「クラウドコンピューティング」として広く普及するに至ったと言える。
仮想化技術 - 柔軟性の実現
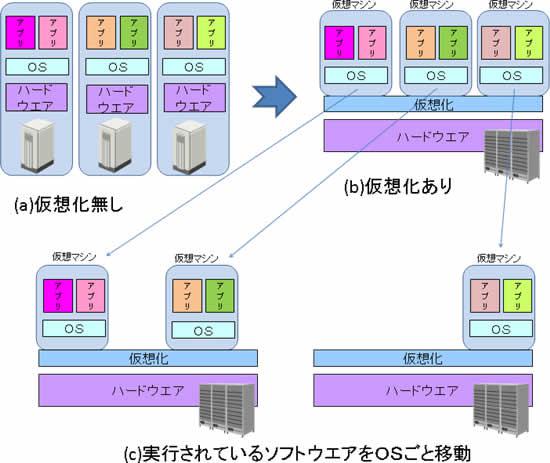
計算機資源を必要に応じて柔軟に再構成するための基本技術に、「仮想化」と呼ばれる技術がある。従来は1つの計算機ハードウェアの中に1つのオペレーティングシステム(OS:メモリ、ディスク、CPUなどのハードウェア資源を管理する基本ソフトウェア )が実装され、その上でアプリケーションソフトウェアを動かしていた(図1の(a))。これに対し「仮想化」技術では、OSとハードウェアとの間に仮想化ソフトウェアを挟むことで、アプリケーションやOSが実際には1つしかないハードウェアを共有しているにもかかわらず、それぞれがあたかも専用のハードウェア(仮想マシン)の上で動いているように見せかけることができる(図1の(b))。
最新の仮想化ソフトウェアは、その上で動作しているOSやアプリをそのまま、仮想マシンごと別のハードウェアの上に移動してしまうことができる(図1の(c))。ちょうど座布団に座っている人を、本人に気づかれないように座布団ごと別の部屋へ動かしてしまうようなものである。この技術を用いると、例えばアプリケーションによる情報処理量が増えて、1つのハードウェア上で多くの仮想マシンを動かしていたのでは処理が追いつかなくなる場合に、新しいハードウェアを用意し、いくつかの仮想マシンをそちらへ移すことで、処理の増大に対処することができるようになる。逆に処理量が減少してきたら、それまでは別々のハードウェア上で動作させていた処理を1つのハードウェア上にまとめ(縮退させ)、空いたハードウェアの電源を切って節電することも可能となる。
さらに仮想マシンは、物理的なマシンと異なり、ソフトウェア的な制御で柔軟に生成したり消滅したりさせることが容易になる。処理量に応じて仮想マシンの数を増減させ、複数のハードウェアの上に適切に配置することで、ハードウェアを効率的に活用しつつ、処理量の増減に柔軟に対応できる。
例えば、ウェブサイトを作るような場合には、そのサイトの人気がどれくらい高くなり、どれくらいのアクセスが集中するのかをあらかじめ見極めることは大変難しいが、仮想化の技術を応用すれば、アクセスの度合いに応じて処理能力を迅速、柔軟に変化させられる。これにより、無駄な投資の危険性を最小限に抑え、ビジネス立ち上げのハードルを極めて低くすることが可能となった。
並列処理の実現 - 大規模データの処理
「並列化」については、処理する数(並列度)を増やせば「全体の処理能力も増える」と直感的には思えるが、実際に処理能力を増やすことは容易でない場合も多い。例えば「大量のデータから必要なものを見つける」といった処理を、並列に行うことを考えてみよう。大量のデータをたくさんの仮想マシンに分割し、それらの仮想マシンにやるべき仕事を与え、各仮想マシンで処理が完了したら結果を集めてくる、といった処理をきちんとプログラムする必要がある。仮想マシンの数が変動するような場合にも対応しようとすると、そのプログラムは複雑化する。さらに、大量のハードウェアを並列に動かす場合には、その故障についても考慮しなくてはならない。1台のハードウェアの故障率が低くても、その数が膨大になれば「いつもどこかで故障が起きている」ということを前提としてプログラムを作成する必要がある。このため、大変複雑なソフトウェアとなることは想像できるだろう。
これに対して、並列処理のための複雑な処理を基本ソフトとして提供し、アプリケーションのプログラマーが複雑さを意識せずに、簡単に並列処理プログラムを作成できるようにするアイディアが、Google社の技術者によって発表された。「GFS:Google File System」という分散ファイルシステムと、「MapReduce」という分散プログラムフレームワークである。このアイディアをオープンソースで実現したHadoopも公開され、多くの人が手軽にクラウド的分散処理を実現できるようになった。
クラウドコンピューティングの社会的影響
「仮想化」と「並列化」により、大規模な情報処理能力を容易に柔軟に実現でき、その処理能力を、インターネットを介して、いつでもどこからでも利用できるようになった。大規模な情報処理事業者は、空いているハードウェアを活用することで、極めて安価にクラウドサービスを提供できる。小さな規模の場合は無料で仮想マシンを貸し出し、それを超えた場合でも極めて安い単価でレンタルするクラウドサービス業者もいくつか現れている。3月の東日本大震災では多くの情報処理システムが被災し、自治体サイトなどへの急激なアクセスの増大による障害も多数発生したが、クラウドサービスの活用でそうした困難を乗り越えることができたという事例も多く見られた。
クラウドの技術を利用して、多くのデータを集約、分析し、活用することも進んでいる。「SNS(ソーシャル・ネットワーキング・サービス)」と言われる情報サービスは、クラウドの大規模な情報集積力と並列処理能力を活用した情報検索、情報分析を背景として成立しているシステムである。スマートフォン利用者の情報検索履歴や位置情報を刻々と集め、それに基づいて適切な広告や案内を提示するサービスも広く行われるようになっている。
大量に集められた情報に対して大規模な分析が行われると、情報が単独で存在していたときにはあまり問題にならなかった「プライバシー侵害」の可能性が生まれてくる。例えば、個々の情報が匿名で集められていたとしても、買い物や旅行、飲食などの履歴をすべて集約すれば、個人の特定が容易になる可能性もある。こういった状況に対応できる、新たなプライバシー保護への取り組みが必要である。その際には単に保護するだけでなく、「保護しつつも、いかにそこから利便性を享受するか」といった“トレードオフ的”な考え方も重要である。
また、クラウドコンピューティングは情報処理システムに関し、「所有」から「利用」へのシフトといった変化をもたらしつつある。これは、情報処理産業の構造へ大きな影響を与える可能性がある。
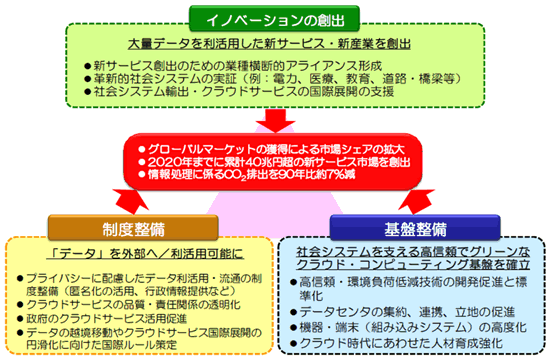
2009年度から2010年度にかけ、経済産業省、総務省はクラウドコンピューティングに関する研究会を相次いで立ち上げ、クラウドが生活や産業にもたらす影響について検討を行った(図2)。この新しい技術をいかに活用するか、大胆な取り組みが必要である。
(たしろ しゅういち)
田代 秀一(たしろ しゅういち) 氏のプロフィール:
1987年筑波大学大学院博士課程工学研究科修了、経済産業省工業技術院電子技術総合研究所入所。工学博士。2006年独立行政法人情報処理推進機構オープンソフトウエアセンター長。2011年から現職。