

三好建正(みよし たけまさ)理化学研究所計算科学研究機構データ同化研究チームリーダーが2016年5月19日、日本気象学会賞を受賞した。この賞は、気象学及び気象技術に関し貴重な研究をなした者に対して贈られる。受賞理由となった「アンサンブルカルマンフィルタによるデータ同化の高度化に関する研究」とは、私たちが日々目にする天気予報の精度向上のための基礎的な研究だ。さらに三好氏はこの研究の先に、新しい天気予報の姿を見ている。どのような天気予報をどんな技術で可能にするのか。三好氏が進める「データ同化」の研究開発に、詳しく迫ってみたい。
現実世界と計算世界を結ぶデータ同化
スマホからのアラーム音。「まもなく雨です。」街中を歩いていたあなたがおもむろに傘をさすと、ポツンと雨が傘をたたく音。近い将来、雨に髪をぬらしてから傘をさす人などいなくなるかもしれない。
こんな未来を語る三好氏は、今、最新鋭の気象測器から送られる膨大な気象観測データとスーパーコンピュータ「京」を駆使して、ゲリラ豪雨などの短時間の気象現象の予測に挑んでいる。「ゲリラ豪雨とは、突然やってくるからゲリラなんです。いつ、どこで起こるか分かったらゲリラじゃない」三好氏らの研究によって“ゲリラ豪雨”は死語となるだろう。
天気予報を支える2大要素は、「観測データ」と「数値モデル」だ。観測によって得られたある瞬間の気象状態をもとに、数値モデルを使って未来の状態を計算する、これが天気予報の基本的なアイデアである。ただ数値モデルは完璧ではなく、観測データも誤差を含んでいる。そのため、ある観測データから計算を始めても、長い時間予測計算をするうちに誤差が膨らみ、現実の大気とのずれは大きくなってしまう。正確な予報をするための解決策のひとつは、“よりもっともらしい大気状態”から予報計算をスタートすることだ。そこで、観測データと数値モデルの計算結果から“よりもっともらしい大気状態”を推定するために「データ同化」という手法が使われる。
「データ同化とは、仮想世界のシミュレーションと現実世界の観測データを結ぶ橋のようなもの」と三好氏。数値モデルにより、時々刻々変動する大気の状態を計算しながら、適当な時間間隔で観測データと突き合わせ、双方の誤差が小さくなるように大気状態を計算していく(図1)。これを繰り返すことで、計算結果は過去の多くの観測データの情報を持った“よりもっともらしい大気状態”となるのだ。図2には、観測データも数値モデルも同じで、データ同化の手法のみが異なる2つの台風予報の結果が示されている。データ同化が天気予報にいかに重要かがよく分かる。
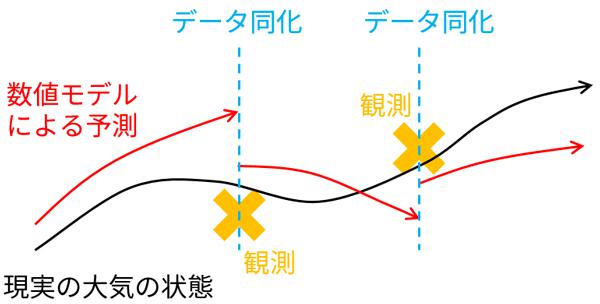
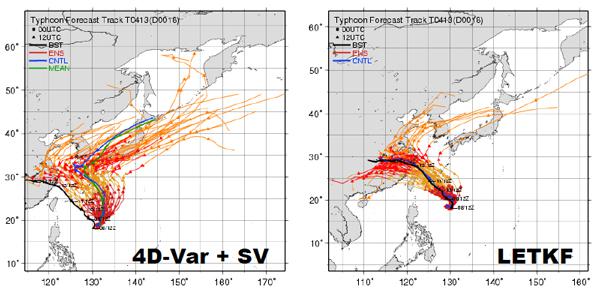
黒線が実際の台風の進路。青線が予報進路。左右の図では、異なるデータ同化手法が用いられている。この予報では、左図は台風の予報進路が東にそれているのに対し、右図は実際の進路とよく合っている。データ同化手法の扱いが、天気予報の精度を大きく左右することが分かる。(出典:三好氏講演資料 Miyoshi et al., 2008, Developments of a local ensemble transform Kalman filter with JMA global model)
積乱雲のスピードと勝負しゲリラ豪雨に挑む
ゲリラ豪雨の生みの親「積乱雲」は、30分という短い時間の中で、発生して、急速に発達し、消滅していく。とても短命で、その水平的な広がりも数キロメートルと、天気予報でおなじみの高気圧や前線などと比べるとずっと規模が小さい。30分で一生を終える相手をコンピュータで再現するためには、その発達の様子を捉えられるほどの短い時間間隔で得られた観測データをもとに、データ同化をする必要がある。白羽の矢が立ったのは、30秒毎に積乱雲全体を観測できる「フェーズドアレイ気象レーダ」と「ひまわり8号」だった。
フェーズドアレイ気象レーダ※1は、雨粒を捕らえる最新型の気象レーダ。従来型のパラボラ式気象レーダはアンテナの向いている方向の雨粒しか観測できないため、雨雲の3次元的な構造を観測するためには、アンテナを縦横に振って5分程度、観測しなければならない。一方フェーズドアレイ気象レーダは、面的に雨粒の分布を観測できるため、アンテナを一周させるだけで全方位の観測ができる。その間わずか30秒。現在、日本に4基しかない(大阪、神戸、沖縄、つくば)。
※1 フェーズドアレイ気象レーダ/情報通信研究機構が2012 年に開発。詳しくはプレスリリース「日本発、フェーズドアレイ気象レーダを開発」を参照のこと。
ひまわり8号※2は2015年7月7日から本格運用が始まった次世代型の気象観測衛星。3万6千キロメートル上空から日本を含む広範囲の雲の様子などを24時間観測している。“次世代型”と呼ばれる所以は、圧倒的なデータ量だ。より細かく、より短い時間間隔で雲の様子を撮影。地球がすっぽり入る広い領域の観測に加え、30秒毎に1000×500キロメートルの領域を観測し続けることもできるのだ。
※2 ひまわり8号/気象庁の気象衛星。詳しくは、気象庁「新しい静止気象衛星 −ひまわり8号・9号」を参照のこと。
ただ、30秒毎に観測できるということは、30秒毎に膨大なデータが次々と送られてくることを意味する。また、30分で消えてしまう積乱雲を予測する計算に10分、20分もかけていては予報の価値はない。三好氏らはスーパーコンピュータ「京」を駆使して、1分以内に30分後の予報をはじき出そうとしている。実現すれば予報の有効期間は29分。ゲリラ豪雨が予想されても、十分に対処できる時間だ。しかもその予報を30秒毎に更新するという驚きの構想だ。
「未来の天気予報」実現への道
素早く雨雲を観測できる観測装置と、高速で計算できるスパコンをつなげれば、これまでよりも早い天気予報ができるのは当然では?と思われるかもしれないが、もちろんそんなことはない。やはり鍵となるのは、観測と数値モデルをつなぐ橋、データ同化システムの革新的技術開発だ。現在気象庁で行っている天気予報のためのデータ同化は最速でも1時間毎。これを数10秒毎に行うためには、桁違いに高速なデータ処理が必要となる。そのために三好氏は次の3つの点を挙げている。
- 1.スパコンの計算能力を最大限に発揮させ、観測装置や計算機から吐き出される膨大なデータを滞ることなく高速にやり取りするアルゴリズムを開発するため、ハードウェア開発者とソフトウェア開発者がより強い協力体制で開発に臨むこと。
- 2.数値モデルとデータ同化計算の高速化。
- 3.観測サイトにおいて、生データ取得から品質管理、データ処理までを高速に行うための高速処理技術。
これらの課題への挑戦は、今着実に実を結びつつある。図3は、フェーズドアレイ気象レーダの観測をもとにデータ同化と数値予報を試みた結果のひとつだ。右の列が実際に観測された雨の強さ(上から2013年7月13日15:16、15:26、15:36)。中央と左の列は数値予報の結果だ(左はデータ同化無し、中央はデータ同化あり)。データ同化手法を用いた中央の予報の方が、雨が線上に広がっている様子をよく捉えていることが分かる。ゲリラ豪雨の尻尾にもついに手が届きそうだ。しかし、「この予測にはまだ大きな改善点が残っています。特に気になるのが、東側に激しく発達しているエコーで、観測されていない誤った予報です」と三好氏。予測の改善に向けた挑戦は日々続いている。
さらにひまわり8号のデータを使ったテスト計算の結果も出始めている。まだ実際の天気予報には計算速度が足りないが、2020年には「京」の後継機を使っての実証実験も視野に入れている。実現すれば、オリンピック観戦に訪れた海外の旅行者には驚きの“おもてなし”となるだろう。
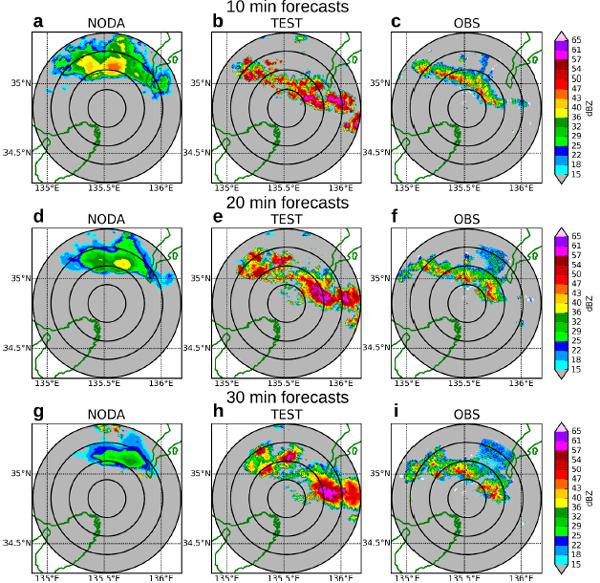
右列 (c、f、i) は観測された雨粒の様子。2013年7月13日15:16 (c)、15:26 (f)、15:36 (i)。中央の列 (b, e, h) はデータ同化手法を用いた数値予報の結果。15:06 から予報を開始し、10分後 (b)、20分後 (e)、30分後 (h) の予報結果。左列 (a、d、g) はデータ同化を用いない場合の数値予報の結果。
(出典:三好氏講演資料「ビッグデータ同化」でゲリラ豪雨に挑む)
「全国一般風ノ向キハ定リナシ天気ハ変リ易シ但シ雨天勝チ」(1884年日本発の天気予報より、午前6時の予報 出典:饒村曜、1984、「天気予報100年」、天気、31、pp371-373)
1884年6月1日、日本で初めて行われた天気予報は、1日3回、日本全国をひとつの予報域としたもので、予報文も東京市内の交番に掲示されるという、今では想像もできない形からスタートした。130年以上経った今、私たちはテレビやスマホなどを通じて、常に、しかも、私の街の数時間後の天気予報を知ることができる。そして10年後、私たちの天気予報観はさらに変わっているに違いない。天気とどのように付き合っているのか、今からわくわくしてしまう。
科学コミュニケーター 大西 将徳